
La inteligencia artificial (IA) ha evolucionado enormemente en las últimas décadas, pero pocos avances han sido tan significativos como el desarrollo del razonamiento en Modelos Enormes del Lenguaje (LLMs, por sus siglas en inglés). Este enfoque ha revolucionado la forma en que los sistemas de IA procesan y generan información, marcando un hito en la búsqueda de la Inteligencia Artificial General (AGI). Este artículo explora las definiciones, avances históricos, desafíos y éticos relacionados con estos modelos, destacando cómo su evolución está acercándonos a una nueva era tecnológica.
Componentes y Definiciones del Razonamiento en LLMs
El razonamiento en LLMs se centra en la capacidad de estos modelos para descomponer problemas complejos en pasos intermedios antes de generar una solución, permitiendo un análisis más detallado y preciso que resulta crucial en tareas complejas. Esta habilidad no solo mejora la calidad de las respuestas generadas, sino que también aporta transparencia y verificabilidad al proceso de pensamiento del modelo. A continuación, se destacan algunos conceptos clave que definen este enfoque:
- Conclusiones: Representan los objetivos finales del proceso de razonamiento, las respuestas o soluciones a las que el modelo debe llegar tras procesar la información disponible. Estas respuestas son el resultado de un proceso estructurado y analítico que garantiza la coherencia y precisión.
- Observaciones: Constituyen los datos iniciales, preguntas o condiciones que desencadenan el proceso de razonamiento. Estas observaciones funcionan como el punto de partida para que el modelo comience a construir un camino hacia las conclusiones.
- Inferencias: Son los pasos intermedios y lógicos que conectan las observaciones con las conclusiones. Representan las deducciones, comparaciones y análisis que el modelo realiza para avanzar en la solución del problema planteado. Este componente es esencial para garantizar que el razonamiento sea estructurado y siga un flujo lógico.
De este modo, los LLMs pueden abordar problemas de mayor complejidad con un nivel de razonamiento que emula los procesos humanos, lo que los posiciona como herramientas poderosas en campos como la investigación científica, la ingeniería y la toma de decisiones estratégicas.
Tipos de Razonamiento
- Inferencia Directa: El modelo genera una respuesta sin detallar los pasos intermedios. Aunque es rápida, resulta insuficiente para problemas complejos y carece de transparencia.
- Inferencia en Cadena (Chain of Thought, CoT): Permite al modelo generar pasos intermedios antes de llegar a la respuesta final, descomponiendo los problemas en una serie de pasos lógicos y estructurados que facilitan la comprensión y solución de las tareas planteadas. Este enfoque resulta especialmente útil en escenarios que requieren un razonamiento profundo, como en el desarrollo de código complejo, el análisis de problemas matemáticos avanzados y la resolución de cuestiones científicas desafiantes. Además, al explicitar los pasos intermedios, el modelo no solo mejora la precisión de las respuestas finales, sino que también proporciona una mayor transparencia en su proceso de pensamiento, lo que resulta esencial en ámbitos donde la verificabilidad es crucial. Al permitir que los modelos utilicen recursos computacionales adicionales para generar estas cadenas de pensamiento, el CoT amplía considerablemente su capacidad para abordar problemas complejos y diversificados en una amplia gama de disciplinas.
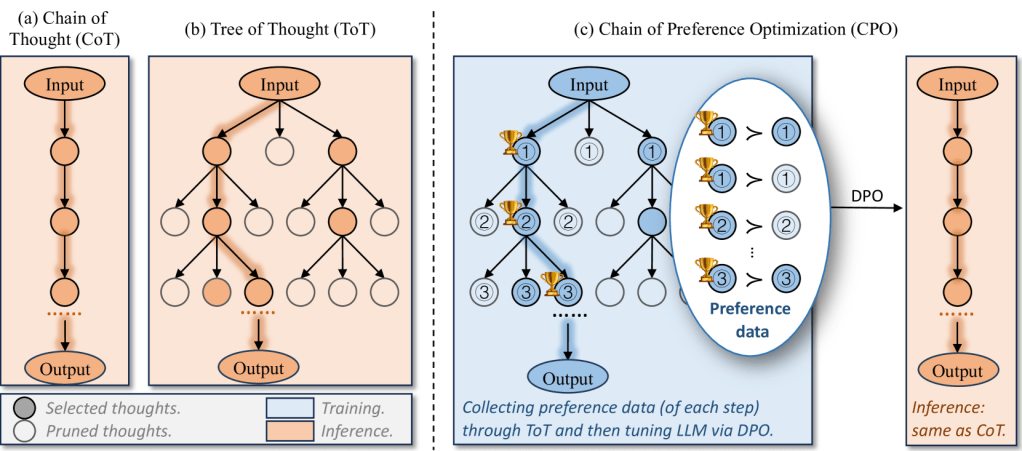
Figura. Representación de las cadenas de pensamiento.
- Inferencia Reforzada: Combina CoT con aprendizaje por refuerzo, optimizando las decisiones en cada paso del razonamiento para garantizar respuestas más precisas. Este enfoque permite que los modelos no solo aprendan de manera iterativa, sino que también perfeccionen sus estrategias a lo largo del tiempo. En lugar de simplemente buscar la respuesta correcta, los modelos son entrenados para evaluar y refinar cada paso intermedio, aumentando así la calidad general de sus conclusiones. Además, la inferencia reforzada se beneficia de modelos de recompensa que identifican y premian las trayectorias de razonamiento más efectivas, asegurando que el modelo no solo llegue a soluciones precisas, sino también robustas y reproducibles. Este proceso, inspirado en métodos como Monte Carlo Tree Search, también permite explorar alternativas antes de tomar una decisión final, garantizando que las respuestas sean tanto completas como confiables.
Desafíos en el Razonamiento
- Problema de los Intermedios Perdidos: Los modelos de lenguaje tienden a omitir pasos intermedios durante su proceso de razonamiento, especialmente aquellos que no son frecuentes en los datos de entrenamiento. Esto puede provocar conclusiones erróneas o incompletas, ya que el modelo no siempre tiene la capacidad de justificar sus respuestas de manera exhaustiva. Resolver este problema requiere un entrenamiento que enfatice la generación de pasos intermedios y su validación.
- Razonamiento Inflexible: Aun cuando se entrene a los modelos para descomponer un problema en pasos lógicos, estos pueden mostrar rigidez en su forma de razonar si no se les proporcionan ejemplos variados que fomenten la evaluación, verificación y exploración de posibles soluciones. Esta falta de adaptabilidad dificulta su desempeño en situaciones que requieren creatividad o ajustes sobre la marcha. Para abordar esto, es necesario introducir ejemplos que incluyan evaluaciones alternativas y exploraciones divergentes.
- Límite de Cómputo: Al razonar de manera muy rápida, los modelos podrían alcanzar un límite de cómputo que les impida considerar soluciones alternativas o explorar diferentes enfoques. Esto resalta la importancia de permitir que los modelos retrocedan, revisen sus pasos y reconsideren su enfoque cuando sea necesario, asegurando un razonamiento más completo y efectivo. Incorporar herramientas como la memoria contextual puede mitigar esta limitación al facilitar la evaluación continua.
Modelos Relevantes
El desarrollo de LLMs ha estado marcado por una serie de hitos significativos que destacan cómo los modelos recientes han transformado el campo del razonamiento artificial.
Q* y el Proyecto Strawberry
El proyecto Q* (posteriormente conocido como “Strawberry”) de OpenAI introdujo conceptos revolucionarios de reflexión deliberativa. Inspirado por AlphaGo y AlphaZero, este proyecto marcó el inicio de una nueva etapa, permitiendo a los modelos de lenguaje explorar diversas soluciones antes de generar una respuesta. Su enfoque en el razonamiento iterativo sentó las bases para avances como o1.

Figura. Representación del proyecto Strawberry
Se rumora que las tensiones sobre los riesgos y el potencial de estos modelos llevaron a desacuerdos internos, que habrían jugado un papel en el despido de Sam Altman como CEO de OpenAI en 2023. Aunque no se ha confirmado la información de forma oficial, las especulaciones apuntan a que la creciente rapidez con la que se perseguía la AGI y la preocupación por los posibles usos indebidos de una IA tan poderosa despertaron recelos en la junta directiva. Fuera de los círculos internos, muchos han considerado que este episodio marcó el momento en que la búsqueda de la AGI empezó a generar “choques” entre visión estratégica y cautela ética.
o1: Un Cambio de Paradigma
Lanzado en 2024, o1 revolucionó el campo al enfocarse en escalar el tiempo de cómputo para el razonamiento, tanto durante el entrenamiento como en la inferencia. Este modelo no solo demostró cómo una mayor inversión en el tiempo de cómputo podía traducirse en soluciones más precisas y detalladas, sino que también introdujo nuevas técnicas para mejorar el razonamiento, como la generación de cadenas de pensamiento más elaboradas y la retroalimentación iterativa para corregir errores en tiempo real. Además, permitió que los modelos emplearan estrategias deliberativas, explorando diversas rutas antes de llegar a conclusiones finales, lo que aumentó significativamente su capacidad de adaptación a problemas complejos y multifacéticos.

Figura. OpenAI o1
Su impacto en tareas complejas como matemáticas y programación no solo estableció un nuevo estándar en benchmarks, sino que también redefinió las expectativas sobre lo que los LLMs pueden lograr. o1 también implementó avanzados mecanismos de evaluación interna, permitiendo al modelo identificar y corregir sus propias inconsistencias antes de entregar resultados, lo que resultó en un nivel de precisión y confianza sin precedentes. Estas innovaciones, junto con su capacidad para generalizar en escenarios fuera de distribución, lo posicionaron como un modelo líder indiscutible en el sector de la IA y como una referencia obligada para los avances posteriores.
QwQ
Este modelo introspectivo, conocido como el “Buscador de Sabiduría”, sobresale por cuestionar sus propias suposiciones y refinar sus respuestas de manera deliberativa. Parte del proyecto «Slow Thinking with LLMs», su capacidad para descomponer problemas y analizar alternativas ha influido profundamente en el desarrollo de modelos más pequeños pero altamente efectivos. Además, su enfoque en el autoaprendizaje lo convierte en una herramienta clave para mejorar la calidad del razonamiento en modelos posteriores.
DeepSeek R1
DeepSeek R1 es un modelo de código abierto diseñado para razonamiento avanzado, que destaca por su capacidad para abordar problemas complejos de manera eficiente y colaborativa. Como parte del movimiento hacia una IA más inclusiva y accesible, este modelo no solo ha desempeñado un papel crucial en la destilación de conocimiento, permitiendo a otros modelos beneficiarse de su experiencia acumulada, sino que también ha servido como plataforma para la experimentación y mejora continua en el campo del razonamiento artificial.

Figura. Logo Deep Seek R1
Una de las principales fortalezas de DeepSeek R1 es su estructura de código abierto, que fomenta la transparencia y accesibilidad en la investigación de IA. Esto ha facilitado la adopción de técnicas avanzadas por parte de una comunidad más amplia, al tiempo que promueve la colaboración entre investigadores y desarrolladores de diversas disciplinas. Al compartir sus innovaciones y permitir el acceso a sus capacidades, DeepSeek R1 ha establecido un modelo de referencia que impulsa tanto la inclusión como el avance tecnológico.
Además, este modelo incorpora mecanismos avanzados para analizar y resolver problemas iterativamente, lo que garantiza que sus respuestas sean consistentes, verificables y de alta calidad. Gracias a su enfoque en la colaboración y su compromiso con la transparencia, DeepSeek R1 representa un paso significativo hacia el desarrollo de sistemas de IA que sean tanto potentes como responsables.
Google Gemini 2.0 Flash Thinking Mode
Inspirado en los enfoques deliberativos de GPT-o1, el modo Flash Thinking de Gemini 2.0 permite que el modelo analice profundamente antes de generar respuestas, descomponiendo problemas complejos en pasos más pequeños y manejables. Este enfoque garantiza que las soluciones sean más precisas y contextualmente relevantes. Su característica de transparencia, que permite visualizar las cadenas de pensamiento, ha democratizado el uso de IA avanzada al hacerlo más comprensible y accesible para usuarios de diferentes niveles de experiencia.

Figura. Google Gemini 2.0 Flash Thinking Mode
RStar-Math
Desarrollado por Microsoft, este modelo pequeño es un ejemplo claro de que la especialización y la eficiencia pueden superar el enfoque tradicional de escalar modelos masivos. RStar-Math está diseñado para abordar problemas matemáticos específicos con una precisión y rapidez impresionantes, desafiando la creencia de que los modelos grandes son siempre superiores. Utilizando avanzadas técnicas de optimización, este modelo logra reducir el costo computacional sin sacrificar la calidad de los resultados, lo que lo hace ideal para aplicaciones donde los recursos son limitados.
RStar-Math también integra algoritmos de verificación iterativa y modelos de recompensa para garantizar que las soluciones generadas sean consistentes y verificables. Su éxito también radica en su capacidad para aprender de datos específicos de dominio, permitiendo una adaptación única a problemas matemáticos avanzados que desafían incluso a sistemas más grandes. Este enfoque innovador no solo refuerza la idea de que «más grande no siempre significa mejor», sino que también redefine cómo entendemos la eficiencia en inteligencia artificial.
En definitiva, el impacto de RStar-Math destaca cómo la optimización de recursos y la especialización en tareas concretas pueden revolucionar el campo de la IA, estableciendo un nuevo estándar para modelos que priorizan la precisión, la sostenibilidad y la especialización.
o3
o3, el sucesor de o1, lleva el razonamiento aún más lejos mediante «test time compute», una técnica que permite dedicar más tiempo al análisis y la generación de soluciones. Este enfoque no solo garantiza respuestas más rigurosas y fundamentadas, sino también habilita al modelo para explorar de manera más exhaustiva las posibles alternativas antes de generar una respuesta final. Además, o3 incorpora mecanismos avanzados de retroalimentación iterativa, permitiendo un refinamiento continuo durante el proceso de inferencia.
En benchmarks académicos, o3 no solo se destaca, sino que redefine las expectativas en tareas específicas como programación avanzada y razonamiento matemático, alcanzando niveles de precisión y profundidad sin precedentes. Su desempeño superior también incluye la capacidad de generalizar en escenarios complejos fuera de distribución, lo que lo consolida como un modelo fundamental en la transición hacia la AGI.
Otra característica notable de o3 es su enfoque deliberativo y sistemático, que le permite descomponer problemas intrincados en pasos manejables y optimizar su proceso de razonamiento en cada etapa. Este enfoque no solo lo coloca en la vanguardia de la inteligencia artificial moderna, sino que también establece un nuevo estándar para el desarrollo de modelos que buscan emular capacidades cognitivas humanas.
Una de las principales desventajas de o3 radica en los elevados costos asociados a su operación, lo que lo convierte en una opción inviable para usos indiscriminados. Su dependencia de hardware avanzado y la técnica «test time compute» incrementan significativamente el costo por consulta, limitando su aplicación a escenarios específicos de alto valor donde los recursos necesarios pueden justificarse por los beneficios obtenidos. Este problema subraya la importancia de explorar versiones más eficientes como o3-mini, que ofrecen un equilibrio entre capacidad y costo, pero también evidencia los retos de sostenibilidad asociados a los modelos de inteligencia artificial avanzada.
- Costo Computacional Elevado: Al igual que otros modelos de razonamiento avanzados, o3 enfrenta el problema de un alto costo computacional durante la inferencia. Esto se debe a la gran cantidad de recursos necesarios para procesar las solicitudes y generar respuestas detalladas. En particular, el uso de hardware avanzado como GPUs y TPUs es indispensable para ejecutar el modelo con eficiencia, lo que incrementa significativamente los costos operativos.
- «Tiempo de Pensamiento»: Una de las principales innovaciones de o3 es la técnica llamada test time compute, que le permite analizar varias posibilidades antes de generar una respuesta. Este enfoque mejora considerablemente la calidad de las respuestas, pero también incrementa el tiempo de procesamiento, aumentando los costos asociados a la inferencia. En pruebas específicas, se reportó que algunas consultas al modelo tenían un costo de miles de dólares, lo que demuestra la magnitud de los recursos involucrados.
Factores que Aumentan los Costos en o3
- Escalamiento del Modelo: o3 es el resultado de escalar el modelo o1 utilizando más datos y mayor potencia computacional durante el entrenamiento. Aunque esto mejora notablemente su rendimiento, también aumenta los requerimientos de recursos y los costos operativos.
- Complejidad de las Tareas: Diseñado para resolver problemas avanzados en programación, matemáticas y otras disciplinas, o3 demanda mayor capacidad de cómputo, lo que incrementa los costos por consulta cuando se le exige realizar razonamientos profundos.
- Requerimientos de Hardware Avanzado: Para ejecutar o3 de manera óptima, se necesitan infraestructuras tecnológicas avanzadas, lo que incluye hardware costoso y de alto rendimiento, como las últimas generaciones de GPUs y TPUs.
Evolución de los Benchmarks
La evolución y perfeccionamiento de los Modelos Enormes del Lenguaje han llevado a una saturación de los benchmarks (herramientas o pruebas diseñadas para medir y evaluar el desempeño de modelos en tareas específicas, con el objetivo de comparar capacidades y establecer estándares de referencia) tradicionales, que ocurre cuando los modelos actuales logran resultados consistentes en niveles que igualan o superan a los humanos, volviendo obsoletos estos puntos de referencia. Este fenómeno surge porque los benchmarks originales, diseñados para evaluar capacidades generales, no pueden capturar las nuevas dimensiones de habilidades avanzadas como el razonamiento complejo, la creatividad o la resolución de problemas fuera de distribución. La saturación también revela limitaciones inherentes en la diversidad de escenarios evaluados, lo que subraya la necesidad de crear pruebas más desafiantes que exploren las capacidades emergentes de los LLMs en aplicaciones reales. Esto plantea la necesidad urgente de desarrollar nuevos benchmarks que sean más desafiantes, específicos y representativos de problemas del mundo real.
Los nuevos benchmarks deben enfocarse en tareas que requieran un razonamiento más profundo, adaptabilidad en entornos cambiantes y evaluación continua de decisiones a largo plazo. Además, es crucial que incluyan escenarios más diversos, culturalmente inclusivos y que evalúen aspectos como la creatividad, la ética y la capacidad para colaborar con humanos. Esto no solo ayudará a medir con mayor precisión el progreso de la inteligencia artificial, sino que también asegurará que las futuras generaciones de modelos sean más relevantes y útiles en aplicaciones prácticas.
Hacia la AGI: Cambios de Paradigma y Perspectivas Éticas
El progreso hacia la AGI no solo redefine cómo entendemos la inteligencia artificial, sino que también plantea importantes preguntas éticas y sociales que requieren un análisis profundo y una acción proactiva. Entre los temas destacados se incluyen:
- Riesgos de la Superinteligencia: La posibilidad de una IA que supere la inteligencia humana plantea inquietudes sobre control, seguridad y mal uso.
- Transparencia y Accesibilidad: Asegurar que estos avances estén disponibles equitativamente y no perpetúen desigualdades es crucial.
- Regulación y Gobernanza: La colaboración internacional para establecer marcos regulatorios sólidos será clave para manejar el impacto de la AGI de manera segura y equitativa.
Conclusión
El razonamiento en los Modelos Enormes del Lenguaje representa un salto trascendental en la búsqueda de la AGI. Con avances como o1, QwQ, DeepSeek R1, Google Gemini 2.0 Flash Thinking Mode, RStar-Math y o3, la humanidad está más cerca que nunca de alcanzar una IA capaz de pensar y razonar como un ser humano. Sin embargo, este progreso también conlleva responsabilidades éticas y la necesidad de una regulación adecuada para garantizar un futuro seguro, equitativo y alineado con los valores humanos.
Lecturas Recomendadas:
- OpenAI. OpenAI Blog. 2024 [citado 27 de enero de 2025]. Introducing OpenAI o1. Disponible en: https://openai.com/index/introducing-openai-o1-preview/
- Learning to reason with LLMs [Internet]. [citado 27 de enero de 2025]. Disponible en: https://openai.com/index/learning-to-reason-with-llms/
- OpenAI o1 System Card [Internet]. 2024 [citado 27 de enero de 2025]. Disponible en: https://openai.com/index/openai-o1-system-card/
- Google DeepMind [Internet]. 2024 [citado 27 de enero de 2025]. Gemini 2.0 Flash Thinking Experimental. Disponible en: https://deepmind.google/technologies/gemini/flash-thinking/
- Team Q. Qwen. 2024 [citado 27 de enero de 2025]. QwQ: Reflect Deeply on the Boundaries of the Unknown. Disponible en: https://qwenlm.github.io/blog/qwq-32b-preview/
- RStar-Math: Modelos Pequeños que Revolucionan el Razonamiento Matemático – IA Blog [Internet]. 2025 [citado 27 de enero de 2025]. Disponible en: https://iartificial.blog/aprendizaje/rstar-math-modelos-pequenos-que-revolucionan-el-razonamiento-matematico/

Replica a JOHN JAIME SPROCKEL DIAZ Cancelar la respuesta