La disrupción provocada por los Modelos Enormes del Lenguaje (Large Languaje Models o LLM) ha permeado muchos aspectos de la sociedad, la medicina no ha sido la excepción. Es así como resulta cada vez más difícil determinar cuál es la mejor opción dentro de la miríada de soluciones que van apareciendo. Esto hace que sea esencial disponer de un marco de evaluación fiable que pueda juzgar con precisión la calidad de los LLM.
El análisis lingüístico es un paso trascendental en el contexto de tareas de procesamiento del lenguaje natural, los principales enfoques detrás de esta tarea podría resumirse en:
- Named Entity Recognition (NER): Es un componente que se enfoca en identificar y clasificar entidades nombradas en el texto, como nombres de personas, lugares, organizaciones, fechas, cantidades, etc. Por ejemplo, en una tarea de análisis de noticias, el NER puede etiquetar los nombres de políticos, países o empresas mencionadas en los artículos.
- Sentiment Analysis: Este enfoque se centra en determinar la polaridad del sentimiento expresado en un texto, como positivo, negativo o neutro. Por ejemplo, en comentarios de productos en línea, el análisis de sentimiento puede clasificar si las opiniones son favorables o desfavorables hacia un producto.
- Coreference Resolution: Es un componente que aborda el problema de identificar menciones en el texto que se refieren a la misma entidad. Por ejemplo, en una tarea de resumen automático de noticias, se necesita resolver la co-referencia para evitar la repetición innecesaria de entidades en el resumen.
- Word Sense Disambiguation (WSD): Este enfoque se enfoca en determinar el significado correcto de una palabra que tiene múltiples sentidos en un contexto específico. Por ejemplo, en una tarea de traducción automática, el WSD puede ayudar a seleccionar la traducción adecuada para una palabra polisémica.
- Paraphrase Detection: Este componente se centra en identificar oraciones o frases que tienen un significado similar pero se expresan de manera diferente. Por ejemplo, en la clasificación de preguntas y respuestas, el detector de paráfrasis puede identificar si dos preguntas tienen el mismo significado aunque tengan diferentes palabras.
- Text Summarization: Enfoque que se encarga de generar resúmenes breves y coherentes a partir de un texto más largo. Por ejemplo, en el resumen de noticias, el sistema puede generar un resumen conciso de los puntos clave de un artículo periodístico.
Existen numerosas métricas que han sido propuestas para el análisis lingüístico de los LLM entre las que podríamos destacar:
BLEU (Bilingual Evaluation Understudy Score) y Rouge (Recall Oriented Understudy for Gisting Evaluation): BLEU es una métrica que se centra en la exactitud (accuracy) y calcula la superposición de n-gramas entre el texto generado y la referencia (texto objetivo). Esta superposición de n-gramas significa que la evaluación es independiente de la posición de las palabras, considerando solo las asociaciones de términos de los n-gramas. Sin embargo, es importante tener en cuenta que BLEU también aplica una penalización por brevedad, lo que significa que se penaliza cuando el texto generado es demasiado corto en comparación con el texto de referencia. Esta penalización busca incentivar que el modelo genere textos más completos y coherentes. Rouge funciona de manera similar, solo que se centra en Recall (sensibilidad) en vez de la exactitud.
Limitaciones de BLEU:
- Falta de sensibilidad semántica: BLEU se basa en la coincidencia de n-gramas y no tiene en cuenta el significado o la semántica de las palabras. Esto puede llevar a que textos generados que son gramaticalmente correctos pero semánticamente incorrectos obtengan altas puntuaciones de BLEU.
- No considera la coherencia global: BLEU evalúa la precisión a nivel de n-gramas, pero no considera la coherencia global del texto generado. Por lo tanto, un texto que tiene coherencia a nivel de oración individual podría no ser coherente en su conjunto.
- Sensibilidad a la longitud del texto: La penalización por brevedad en BLEU puede afectar la evaluación de textos cortos, lo que puede ser problemático cuando se generan resúmenes o respuestas cortas.
Limitaciones de Rouge:
- Sensibilidad a la longitud del resumen: Rouge, al igual que BLEU, también puede ser sensible a la longitud del texto generado en comparación con el resumen de referencia. Esto puede llevar a que los resúmenes más cortos obtengan mejores puntuaciones de Rouge.
- Limitado en la comparación de documentos largos: Rouge suele utilizarse para evaluar la calidad de resúmenes, pero puede no ser tan efectivo para evaluar la calidad de textos más largos o documentos completos.
METEOR (Metric for Evaluation of Translation with Explicit ORdering): es una métrica de evaluación automática utilizada principalmente en tareas de traducción automática y generación de texto. Esta métrica combina la precisión unigram, la correspondencia de frases y una función de penalización para las frases no alineadas para calcular la similitud entre las oraciones generadas y las oraciones de referencia (oraciones humanas). METEOR tiene en cuenta el orden de las palabras en las frases y ha demostrado ser eficaz en capturar aspectos semánticos y gramaticales del texto generado.
CIDEr (Consensus-based Image Description Evaluation) es una métrica de evaluación específicamente diseñada para tareas de generación de descripciones de imágenes en el campo de la visión por computadora. Esta métrica se basa en el consenso entre múltiples evaluadores humanos para calificar las descripciones generadas en función de la relevancia y coherencia con respecto a la imagen de referencia. CIDEr considera tanto las correspondencias de palabras individuales como las similitudes gramaticales en la evaluación.
Algunas de las métricas específicas para el dominio médico son:
BLEURT (Bilingual Evaluation Understudy for Relevance and Trustworthiness): Esta métrica se enfoca en la relevancia y confiabilidad del texto generado, especialmente en tareas de generación de resúmenes de documentos médicos y en traducción automática de textos médicos. BLEURT utiliza un modelo de lenguaje pre-entrenado que se entrena específicamente en ejemplos de evaluación humana.
COCO-QA (COCO-Quality Assurance): Esta métrica fue diseñada para evaluar la calidad y exactitud de las respuestas generadas en preguntas y respuestas relacionadas con el dominio médico. Se basa en la evaluación humana de las respuestas para medir la calidad del modelo.
GPT-3.5 Med:Metric: Es una métrica específica para evaluar el rendimiento de modelos de lenguaje en tareas médicas. Utiliza preguntas médicas con respuestas humanas de referencia para evaluar la precisión y relevancia de las respuestas generadas por el modelo.
Es común utilizar múltiples métricas de evaluación en conjunto para obtener una visión más completa del rendimiento del modelo. Es importante destacar que el análisis lingüístico en tareas de procesamiento del lenguaje natural puede involucrar una variedad de componentes y enfoques, dependiendo de la naturaleza de la tarea y los objetivos específicos del análisis. Cada componente ayuda a guiar y estructurar el procesamiento del lenguaje para lograr una mayor comprensión y resolución de tareas lingüísticas complejas. El marco SuperGLUE propone los siguientes componentes para el análisis lingüístico:
- Semántica léxica: centrado en el significado de las palabras y su relación con otros elementos lingüísticos en el contexto de una oración o discurso. Sus componentes son:
- Vinculación Léxica: Se refiere a la relación semántica que existe entre una palabra y otras palabras en una oración. Por ejemplo, en la oración «El perro ladra», la palabra «perro» está vinculada léxicamente con la acción de «ladra», lo que indica que el sujeto es quien realiza la acción.
- Negación Morfológica: Es la presencia de un prefijo o sufijo que cambia el significado de una palabra para expresar negación. Por ejemplo, en la palabra «inseguro», el prefijo «in-» indica negación, y el significado es lo opuesto a «seguro».
- Factividad: Es la propiedad de ciertas palabras o expresiones que indican que lo que se está afirmando es un hecho verdadero o indiscutible. Por ejemplo, en la oración «El sol es una estrella», la palabra «es» implica un hecho real o una afirmación verdadera.
- Simetría/Colectividad: Se refiere a la capacidad de ciertas palabras para expresar una relación simétrica o colectiva entre elementos. Por ejemplo, en la oración «Pedro y María se saludan», el verbo «saludan» muestra una relación simétrica entre Pedro y María, ya que ambos se saludan mutuamente.
- Redundancia: Es la repetición de información o significado en una oración o discurso, generalmente con el propósito de enfatizar o aclarar una idea. Por ejemplo, en la oración «Sube arriba», la palabra «arriba» es redundante, ya que «subir» implica movimiento hacia una posición más alta.
- Entidades Nombradas: Son palabras que se refieren a nombres propios de personas, lugares, organizaciones, etc. Estas palabras tienen un significado específico y se utilizan para identificar entidades particulares. Por ejemplo, «John», «New York» y «Google» son entidades nombradas. Aquí se torna importante el reconocimiento de las siglas.
- Cuantificadores: Son palabras que indican la cantidad o el número de elementos en una oración. Los cuantificadores pueden ser específicos (como «dos», «algunos», «todos») o generales (como «muchos», «pocos», «ninguno»). Por ejemplo, en la oración «Hay algunos libros en la mesa», el cuantificador «algunos» indica una cantidad indefinida de libros.
- Estructura predicado-argumento: Cuyos componentes son:
- Ambigüedad Sintáctica: Se refiere a situaciones en las que una oración puede tener más de un significado debido a la estructura gramatical.
- Frases Preposicionales: Son grupos de palabras que incluyen una preposición y un complemento. Por ejemplo, en la oración «El libro está en la mesa», la frase preposicional «en la mesa» indica la ubicación del libro.
- Argumentos Nucleares: Son los elementos principales de un predicado y expresan los participantes fundamentales en una situación. Por ejemplo, en la oración «Juan come una manzana», «Juan» es el sujeto (argumento agente) y «una manzana» es el objeto directo (argumento paciente).
- Alternancias: Se refieren a diferentes formas gramaticales que un verbo puede tomar para expresar diferentes relaciones semánticas. Por ejemplo, las alternancias entre activa y pasiva, genitivo y partitivo, nominalización, dativo, entre otras.
- Elipsis e Implicaturas: La elipsis es la omisión de elementos que son recuperables en el contexto. Las implicaturas son inferencias no explícitas basadas en el contexto. Por ejemplo, en la oración «Ana habla español y Pedro inglés», se omite el verbo «habla» en la segunda parte debido a la elipsis.
- Anáfora y Coreferencia: La anáfora es la referencia a un elemento previo en el texto, mientras que la coreferencia es cuando dos o más expresiones se refieren al mismo elemento. Por ejemplo, en la oración «Juan compró una camisa. Él la lleva puesta», «él» es una anáfora que se refiere a «Juan» y «la» es una coreferencia que se refiere a «camisa».
- Intersectividad: Se refiere a la capacidad de un verbo para tomar varios argumentos del mismo tipo. Por ejemplo, el verbo «comer» puede tener varios argumentos de tipo «comida» en una oración.
- Restrictividad: Se refiere a la capacidad de ciertos modificadores para restringir o limitar el alcance de un sustantivo. Por ejemplo, en «los libros interesantes», el adjetivo «interesantes» restringe el conjunto de libros a aquellos que son interesantes.
- Lógica
- Estructura Proposicional: Es la parte de la lógica que se ocupa del estudio de proposiciones y sus conectores lógicos. Las proposiciones son declaraciones que pueden ser verdaderas o falsas, y los conectores lógicos (como «y», «o», «no», «si… entonces») se utilizan para construir expresiones lógicas más complejas.
- Cuantificación: La cuantificación se refiere a la expresión de afirmaciones generales sobre un conjunto de elementos. La cuantificación se puede hacer de manera universal (para todos los elementos) o existencial (al menos un elemento). Por ejemplo, «Todos los pájaros vuelan» es una afirmación universal, mientras que «Existe un perro en el parque» es una afirmación existencial.
- Monotonicidad: En lógica, la monotonicidad se refiere a cómo cambian las conclusiones a medida que se agregan más información. Un razonamiento es monótono si añadir más premisas no invalida las conclusiones previas. Por ejemplo, si sabemos que «Todos los pájaros vuelan» y luego agregamos «Todos los cuervos son pájaros», la conclusión de que «Todos los cuervos vuelan» sigue siendo válida.
- Estructura Lógica Más Rica: Se refiere a la capacidad de la lógica para manejar estructuras más complejas y sofisticadas. Esto incluye la capacidad de representar relaciones causales, inferencias abductivas (razonamiento basado en la mejor explicación), relaciones temporales y espaciales, entre otras.
- Conocimiento y sentido común: se refiere a la comprensión y conocimiento que poseemos sobre el mundo que nos rodea y las reglas básicas que guían nuestra vida diaria:
- Conocimiento del Mundo: En esta categoría nos enfocamos en el conocimiento que se puede expresar claramente como hechos, así como en el conocimiento geográfico, legal, político, técnico o cultural más amplio y menos común.
- Razonamiento con Sentido Común: se enfoca en el conocimiento que es más difícil de expresar como hechos y que esperamos que posea la mayoría de las personas, independientemente de sus antecedentes culturales o educativos. Esto incluye una comprensión básica de la dinámica física y social, así como el significado léxico (más allá de la simple vinculación léxica o las relaciones lógicas)
- Dominio: El dominio se refiere al campo o área temática en la que se centra la tarea o el conjunto de datos en cuestión. Por ejemplo, el dominio puede ser la medicina, el derecho, la tecnología, etc. En el análisis lingüístico, se debe considerar el dominio para adaptar el modelo del lenguaje y asegurar que comprenda el vocabulario, las entidades y los conceptos específicos del dominio.
- Premisa: En el contexto de tareas de comprensión de lectura o inferencia textual, la premisa es la oración o el fragmento de texto que proporciona la información inicial o el contexto para resolver una pregunta o hacer una inferencia. La comprensión precisa de la premisa es fundamental para responder correctamente a las preguntas o inferir nueva información.
- Hipótesis: En las tareas de inferencia textual, la hipótesis es una oración o proposición que se evalúa o compara con la premisa para determinar si es verdadera o coherente en el contexto dado. La hipótesis es una suposición que se prueba o verifica a partir de la información proporcionada en la premisa.
Los cuatro últimos componentes son particularmente relevantes en tareas que requieren razonamiento y comprensión profunda del texto, donde se debe establecer una relación entre la premisa y la hipótesis para llegar a una conclusión o inferencia.
Se ha demostrado que las métricas automáticas a menudo no se correlacionan con la calidad de los resúmenes. Además de que no existe una métrica de evaluación automática lista para usar diseñada específicamente para evaluar la factualidad de los resúmenes generados por los sistemas de resumen más recientes basados en LLM.
¿Qué tenemos en el Dominio Médico?:
En un esfuerzo de informáticos y médicos de varias universidades lideradas por Tang se realizó una evaluación humana amplia de los resúmenes generados por LLM con el objetivo de obtener una comprensión completa de sus capacidades de resumen. Se pudo documentar la falta de terminología estandarizada para los tipos de errores en el resumen de evidencia médica por lo que se requirió usar la evaluación humana para inventar nuevas definiciones de errores. Los métodos de evaluación se basaron en métodos cualitativos de la teoría fundamentada (grounded theory), lo que implicó el análisis abierto de descripciones cualitativas de inconsistencias factuales, lo que contribuyó al desarrollo de definiciones de errores. Además, incluyeron una medida de la percepción del potencial de daño, ya que es un resultado clínicamente relevante que las métricas automáticas no pueden capturar. La evaluación definió la calidad del resumen a lo largo de cuatro dimensiones:
- Coherencia: Se refiere a la capacidad de un resumen para crear una información coherente sobre un tema mediante conexiones entre las oraciones.
- Consistencia Factual: Mide si las afirmaciones en el resumen están respaldadas por el documento fuente. Dado que los resúmenes de evidencia médica deben ser precisos, para comprender los tipos de errores de inconsistencia factual que producen los LLM, los errores fueron clasificados en tres tipos mediante el análisis abierto de los comentarios de los anotadores:
- De mala interpretación:
- Contradicción: Discrepancia entre las conclusiones extraídas de los resultados de la evidencia médica y el resumen
- Ilusión de certeza: Inconsistencia en el grado de certeza entre el resumen y el documento fuente
- Fabricados: No se puede encontrar evidencia del documento fuente para apoyar o refutar la declaración.
- De atributos:
- Atributo fabricado: Incorporar un atributo para un síntoma o resultado específico al que no se hace referencia en el documento de origen.
- Atributo omitido: Descuidar un atributo para un síntoma o resultado específico
- Atributo distorsionado: Generar atributo incorrecto
- De mala interpretación:
- Comprensividad: Se refiere a si un resumen contiene información completa para respaldar la revisión.
- Daño: Evalúa el potencial de un resumen para causar daño físico o psicológico o cambios no deseados en la terapia o el cumplimiento debido a la mala interpretación de la información.
Cada una de las categorías fue graduada en cinco niveles: fuertemente a favor, a favor, neutral, en contra y fuertemente en contra. Luego se presentaron de forma de gráficos de barra discriminado por temas como aparece en la figura a continuación:
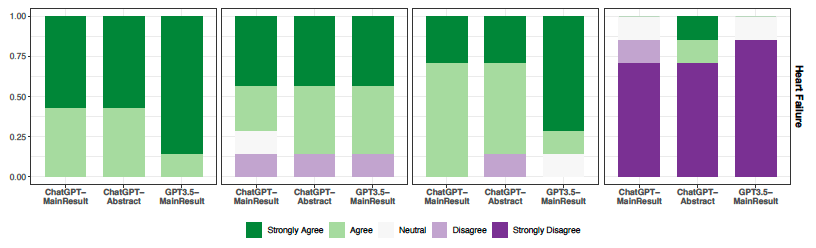
Tomado sin modificar de Tang L, et al.
Lecturas Recomendadas
- Tripathi GP. How to Evaluate a Large Language Model (LLM)? [Internet]. Analytics Vidhya. 2023 [citado 22 de julio de 2023]. Disponible en: https://www.analyticsvidhya.com/blog/2023/05/how-to-evaluate-a-large-language-model-llm/
- Wołk K, Marasek K. Enhanced Bilingual Evaluation Understudy [Internet]. arXiv; 2015 [citado 22 de julio de 2023]. Disponible en: http://arxiv.org/abs/1509.09088
- Dayal D. Medium. 2020 [citado 22 de julio de 2023]. How to evaluate Text Generation Models ? Metrics for Automatic Evaluation of NLP Models. Disponible en: https://towardsdatascience.com/how-to-evaluate-text-generation-models-metrics-for-automatic-evaluation-of-nlp-models-e1c251b04ec1
- Vedantam R, Zitnick CL, Parikh D. CIDEr: Consensus-based Image Description Evaluation [Internet]. arXiv; 2015 [citado 23 de julio de 2023]. Disponible en: http://arxiv.org/abs/1411.5726
- Wang A, Pruksachatkun Y, Nangia N, Singh A, Michael J, Hill F, et al. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems [Internet]. arXiv; 2020 [citado 22 de julio de 2023]. Disponible en: http://arxiv.org/abs/1905.00537
- Tang L, Sun Z, Idnay B, Nestor JG, Soroush A, Elias PA, et al. Evaluating Large Language Models on Medical Evidence Summarization. medRxiv. 24 de abril de 2023;2023.04.22.23288967.

Deja un comentario