Podríamos resumir el proceso de los LLM en los pasos expuestos en la siguiente figura:
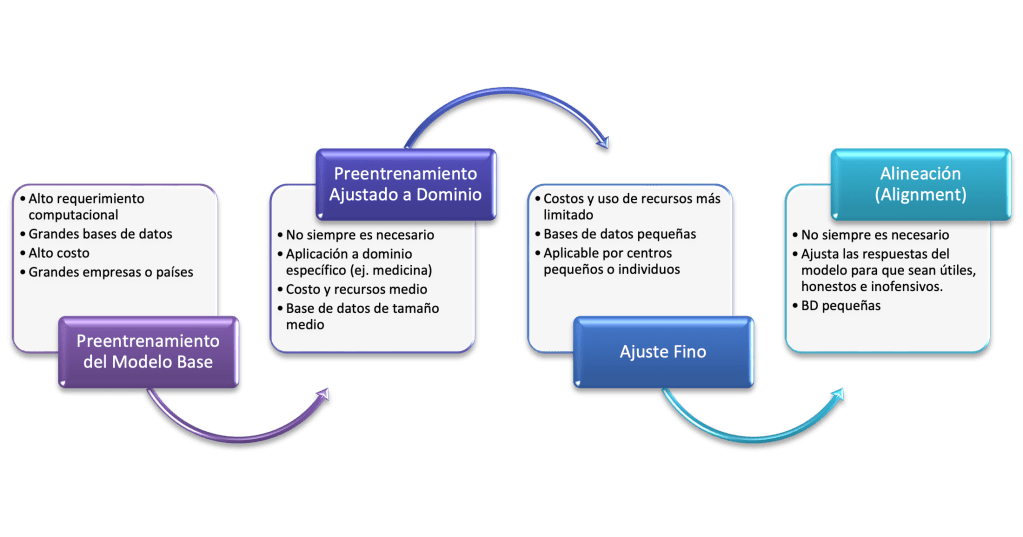
- Preentrenamiento del modelo base: el gran avance en el entrenamiento de estos modelos fue alcanzado gracias a la aplicación del aprendizaje auto-supervisado en el que se enmascara de forma automática una palabra dentro de una oración que durante el entrenamiento el modelo debía completar calculando diferentes probabilidades. Este paso solo requiere dividir en oraciones el texto en el que se constituyen las bases de datos gigantescas no estructuradas con lo que se evitan los grandes costo tanto económicos como de recursos para etiquetar los datos en los modelos tradicionales (1. Wei).
Esta fase no está disponible para la gran mayoría de los investigadores de IA. El acceso a esta tecnología ha estado principalmente restringido a grandes empresas tecnológicas debido al alto costo del esta primera fase, que se estima en alrededor de $10 millones de dólares o incluso más para modelos grandes; requiriendo disponer de un gran número de unidades de procesamiento gráfico (GPU) en físico o más frecuentemente en la nube que además dispongan de más de 1 trillón de tokens dentro de sus bases de datos.
Por fortuna, en la actualidad se están dedicando ingentes esfuerzos para optimizar esta fase y así hacerla más económica, rápida y disponible como el uso de FlashAttention (2. Dao) sobre el que se soportó el entrenamiento del modelo Falcon del Technology Innovation Institute (TII) (3. Falcon) y la técnica de optimización Sophia de la Universidad de Stanford (4. Liu).
2. Preentrenamiento ajustado a dominio: Consiste en extender el proceso anterior en una base de datos específica del dominio al que se pretenda aplicar. Se trata de una fase opcional dentro del proceso de entrenamiento de los LLM. Fue propuesto para los primeros modelos basados en transformers en los que se demostró que el preentrenamiento adaptativo ofrece grandes ganancias en el desempeño de tareas (5. Gururangan). Se ha establecido que esta estrategia permitiría disponer de modelos más pequeños para la tarea específica con la consiguiente disminución de los costos y el tiempo de entrenamiento.
3. Ajuste fino (Fine Tuning): Se trata de ajustar y adaptar un modelo preentrenado para que realice tareas específicas o se adapte mejor a un ámbito concreto. Para ello, suele ser necesario entrenar el modelo en un conjunto de datos más pequeño y específico que sea relevante para la tarea o el tema deseados. El ajuste fino aprovecha este conocimiento general adquirido durante el preentrenamiento y refina el modelo para lograr un mejor rendimiento y comprensión en un dominio específico (6. Dilmegani). Se requiere que los ejemplos de entrenamiento sean presentados de la manera como se requiere que el modelo genere las respuestas, por lo tanto es una fase de aprendizaje supervisado.
Existen varios métodos de ajuste que pueden utilizarse para ajustar los pesos y parámetros de un modelo preentrenado con el fin de mejorar su rendimiento en la tarea objetivo (6. Dilmegani):
- Aprendizaje por transferencia (Transfer learning): Es un método de ajuste que consiste en reutilizar los pesos y la arquitectura de un modelo preentrenado para una nueva tarea o dominio. El modelo preentrenado se suele entrenar en un gran conjunto de datos generales, y el método de aprendizaje por transferencia permite una adaptación eficiente y eficaz a tareas o dominios específicos.
- Ajuste fino secuencial (Sequential fine-tuning): Es un método en el que un modelo preentrenado se ajusta secuencialmente en varias tareas o dominios relacionados. Esto permite que el modelo aprenda patrones lingüísticos más matizados y complejos en distintas tareas, lo que mejora la generalización y el rendimiento.
- Ajuste específico de tareas (Task-specific fine-tuning): Es un método en el que el modelo preentrenado se ajusta a una tarea o dominio concretos utilizando un conjunto de datos específico de la tarea. Este método requiere más datos y tiempo que el aprendizaje por transferencia, pero puede dar lugar a un mayor rendimiento en la tarea específica.
- Aprendizaje multitarea: Es un método en el que el modelo preentrenado se perfecciona en varias tareas simultáneamente. Este enfoque permite que el modelo aprenda y aproveche las representaciones compartidas en distintas tareas, lo que mejora la generalización y el rendimiento.
- Entrenamiento por adaptación (Adapter training): Implica la formación de módulos ligeros que se conectan al modelo preformado, lo que permite el ajuste fino en una tarea específica sin afectar al rendimiento del modelo original en otras tareas.
Las razones por las que se puede requerir el ajuste fino de un LLM por varias razones, en función de los requisitos específicos, su sector y sus objetivos. Estas son algunas de las razones más comunes (6. Dilmegani):
- Personalización: A menudo, las empresas tienen necesidades y objetivos únicos que un modelo lingüístico genérico no puede satisfacer. El ajuste fino les permite adaptar el comportamiento del modelo a sus objetivos específicos, como generar contenido de marketing personalizado o comprender el contenido generado por el usuario en su plataforma.
- Sensibilidad de los datos y conformidad: Las empresas que manejan datos sensibles o que operan en entornos regulatorios estrictos pueden necesitar ajustar el modelo para garantizar que respeta los requisitos de privacidad, se adhiere a las directrices de contenido y genera respuestas adecuadas que cumplen con las regulaciones de la industria.
- Lenguaje específico del sector: Muchos sectores utilizan jerga, términos técnicos y vocabulario especializado que pueden no estar bien representados en los datos de entrenamiento generales de un modelo lingüístico de gran tamaño. Ajustar el modelo a los datos específicos del sector le permite comprender y generar respuestas precisas en el contexto del sector de la empresa.
- Mejora del rendimiento: El ajuste fino mejora el rendimiento del modelo en tareas o aplicaciones específicas relevantes para la empresa, como: análisis de sentimientos, clasificación de documentos y extracción de información. Esto puede conducir a una mejor toma de decisiones, una mayor eficiencia y mejores resultados.
- Mejora de la experiencia del usuario: Un modelo perfeccionado puede ofrecer una mejor experiencia de usuario al generar respuestas más precisas, pertinentes y adaptadas al contexto, lo que se traduce en una mayor satisfacción del cliente, en aplicaciones como: Chatbots, Asistentes virtuales y Sistemas de atención al cliente
Un área interesante de investigación en el ajuste fino de LLM es la reducción de los costos de actualización de los parámetros de los modelos. Este es el objetivo del ajuste fino de parámetros eficientes (Parameter-efficient fine-tuning o PEFT), un conjunto de técnicas que intentan reducir la cantidad de parámetros que deben actualizarse. Hay varias técnicas PEFT, una de ellas es la adaptación de bajo rango (low-rank adaptation o LoRA), una técnica que se ha vuelto especialmente popular entre los modelos de lenguaje de código abierto. La idea detrás de LoRA es que ajustar un modelo base en una tarea posterior no requiere actualizar todos sus parámetros. Existe una matriz de baja dimensión que puede representar el espacio de la tarea posterior con una precisión muy alta (7. Dickson).
4. Alineación (Alignment): Hacer modelos de lenguaje más grandes no los hace inherentemente mejores para seguir la intención del usuario. Existe la posibilidad de generar salidas que son falsas, tóxicas o simplemente, no útiles para el usuario (8. Ouyang). Alinear (Alignment) se refiere a la tarea de hacer que los modelos de lenguaje sigan las instrucciones del usuario y produzcan salidas que sean útiles y coherentes con la intención del usuario (9. Leike). El objetivo es hacer que estos modelos sean útiles, honestos e inofensivos (10. Askell).
La técnica de ajuste fino con retroalimentación humana (fine tuning with human feedback) consiste en entrenar un modelo inicial con datos y luego refinarlo mediante retroalimentación humana para mejorar su desempeño en una tarea específica. Dicha retroalimentación puede tomar diferentes formas, como correcciones manuales o evaluaciones subjetivas por parte de los usuarios (8. Ouyang).
La técnica que empleada por OpenAI para ajustar ChatGPT explica en la generación del modelo InstructGPT (8. Ouyang). Utiliza la retroalimentación humana como señal de recompensa para ello un equipo de 40 contratistas etiquetaron datos basados en su desempeño en una prueba de selección, luego recopilaron un conjunto de datos de demostraciones escritas por humanos del comportamiento deseado de salida en las solicitudes. Usaron este conjunto de datos para entrenar modelos iniciales y recopilaron un conjunto de datos más grande para entrenar un modelo de recompensa que predice qué salidas preferirían los etiquetadores humanos en una variedad más amplia de solicitudes API. Utilizaron este conjunto de datos para entrenar un modelo de recompensa que predice qué salidas preferirían los etiquetadores humanos.
Como ocurre con las tareas de ajuste fino, se requieren grandes conjuntos de ejemplos etiquetados o rotulados. Para esta última fase se emplea información privada proveniente de las empresas aunque para entrenar el modelo de recompensa se dispone de:
- OpenAssistant Conversations Dataset (OASST1) que contiene 7213 muestras de preferencias;
- Anthropic HH-RLHF, un conjunto de datos de preferencias sobre la utilidad e inocuidad del asistente de IA que contiene 160 800 etiquetas humanas y
- Stanford Human Preferences Dataset, un conjunto de datos de 385 000 preferencias humanas colectivas sobre respuestas a preguntas/instrucciones en 18 áreas temáticas diferentes, desde cocina hasta asesoramiento legal.
- Por otro lado, Transformer Reinforcement Learning X (trlX) es un marco de entrenamiento distribuido diseñado desde cero para enfocarse en el ajuste fino de modelos de lenguaje grandes con aprendizaje de refuerzo utilizando una función de recompensa proporcionada o un conjunto de datos etiquetados como recompensa. Se ha usado para realizar la optimización de política proximal (PPO) durante el aprendizaje de refuerzo.
Aún no se cuenta con este tipo de base de datos específicamente diseñada para el campo de la medicina. Es posible que por el carácter específico de la tarea, no se requiera llevar a cabo esta tarea.
Una consideración importante es que podría ser que no se requiera llevar a cabo un ajuste fino siendo el aprendizaje en contexto todo lo que se necesita. El aprendizaje en contexto (In-Context Learning), o el aprendizaje de pocos disparos (Few Shot Learning), es el proceso de incluir ejemplos específicos de tareas en el mensaje. Este enfoque es específico para modelos de lenguaje más grandes y sofisticados, ya que los modelos de código abierto aún tienen que lograr la flexibilidad deseada para poder manejar el aprendizaje en contexto (11. Smith). Por lo general, es posible lograr excelentes resultados con este enfoque. Un trabajo reciente investiga las conexiones matemáticas entre la carga de ejemplos en el enunciado (prompt) y el ajuste fino utilizando los mismos ejemplos demostrando que se producen meta-gradientes que se reflejan durante la propagación hacia adelante en el momento de la inferencia. En el caso del ajuste fino, los ejemplos realmente producen gradientes reales que se utilizan para actualizar los pesos. Por lo tanto, parece que el aprendizaje en contexto logra resultados similares al ajuste fino (12. Dai).
Referencias
- Wei J, Tay Y, Bommasani R, Raffel C, Zoph B, Borgeaud S, et al. Emergent Abilities of Large Language Models [Internet]. arXiv; 2022 [citado 29 de abril de 2023]. Disponible en: http://arxiv.org/abs/2206.07682
- Dao T, Fu DY, Ermon S, Rudra A, Ré C. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness [Internet]. arXiv; 2022 [citado 13 de julio de 2023]. Disponible en: http://arxiv.org/abs/2205.14135
- Falcon LLM [Internet]. [citado 13 de julio de 2023]. Disponible en: https://falconllm.tii.ae/
- Liu H, Li Z, Hall D, Liang P, Ma T. Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training [Internet]. arXiv; 2023 [citado 13 de julio de 2023]. Disponible en: http://arxiv.org/abs/2305.14342
- Gururangan S, Marasović A, Swayamdipta S, Lo K, Beltagy I, Downey D, et al. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. En: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics [Internet]. Online: Association for Computational Linguistics; 2020 [citado 11 de julio de 2023]. p. 8342-60. Disponible en: https://aclanthology.org/2020.acl-main.740
- Dilmegani C. GENERATIVE AI , NLP. 2023 [citado 13 de julio de 2023]. LLM Fine Tuning Guide for Enterprises in 2023. Disponible en: https://research.aimultiple.com/llm-fine-tuning/
- Dickson B. The complete guide to LLM fine-tuning – TechTalks [Internet]. 2023 [citado 13 de julio de 2023]. Disponible en: https://bdtechtalks.com/2023/07/10/llm-fine-tuning/
- Ouyang L, Wu J, Jiang X, Almeida D, Wainwright CL, Mishkin P, et al. Training language models to follow instructions with human feedback [Internet]. arXiv; 2022 [citado 17 de abril de 2023]. Disponible en: http://arxiv.org/abs/2203.02155
- Leike J, Krueger D, Everitt T, Martic M, Maini V, Legg S. Scalable agent alignment via reward modeling: a research direction [Internet]. arXiv; 2018 [citado 29 de abril de 2023]. Disponible en: http://arxiv.org/abs/1811.07871
- Askell A, Bai Y, Chen A, Drain D, Ganguli D, Henighan T, et al. A General Language Assistant as a Laboratory for Alignment [Internet]. arXiv; 2021 [citado 29 de abril de 2023]. Disponible en: http://arxiv.org/abs/2112.00861
- Smith S. Medium. 2023 [citado 13 de julio de 2023]. Thinking about fine-tuning an LLM? Here’s 3 considerations before you get started. Disponible en: https://towardsdatascience.com/thinking-about-fine-tuning-an-llm-heres-3-considerations-before-you-get-started-c1f483f293
- Dai D, Sun Y, Dong L, Hao Y, Ma S, Sui Z, et al. Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers [Internet]. arXiv; 2023 [citado 13 de julio de 2023]. Disponible en: http://arxiv.org/abs/2212.10559

Deja un comentario